كانت أواخر التسعينيات فترة ذهبية للإنترنت ونشر المواقع الإلكترونية حول العالم، بما في ذلك العالم العربي. العديد من هذه المواقع لم تعد موجودة. ومع ذلك، وبفضل archive.org، تم الحفاظ على لقطات من العديد من المواقع. قبل عدة سنوات، وجدت في منزل والدي في لبنان كتاب دليل الإنترنت للعالم العربي لعام 2002 الذي نشرته دار النشر العربية العلمية. احتوى الكتاب على آلاف الروابط الإلكترونية من جميع أنحاء العالم العربي. تواصلت مع ناشرها، السيد غسان شيبارو، وطلبت إذنا لاستخدام الروابط في الكتاب لبناء محرك بحث يعمل للعالم العربي يتكامل بشكل صحيح مع لقطات المواقع المؤرشفة في archive.org. بالإضافة إلى ذلك، لم أرد فقط وجود رابط يذهب إلى كل موقع، بل أردت أن يكون هناك صورة محملة مسبقا لكل موقع. بهذه الطريقة، يمكن لمستخدم الموقع فقط النظر إلى لقطة قبل أن يقرر ما إذا كان يريد مشاهدة الموقع الفعلي في archive.org. ثم شرعت في تطوير الكود الخاص بي لاستخراج حوالي 12000 رابط من الكتاب.
في البداية، كنت أحاول تعديل الكتاب حتى أعطاني السيد شيبارو مستند وورد يحتوي على الروابط، مما وفر علي الكثير من الوقت في استخراج الروابط. كما ترجمت الأوصاف في الكتاب بحيث يتم تمثيل إشارات الموقع باللغتين العربية والإنجليزية. بعد ذلك طورت سكريبت لالتقاط أقدم لقطة لكل موقع على archive.org ، ثم أخذت صورة مصغرة وصورة كبيرة لكل صفحة رئيسية من الموقع، وخزنتها على الكمبيوتر. كان علي أيضا جعل السكريبت ذكيا بما يكفي للتعامل مع عمليات الاسترجاع، وقطع الإنترنت، وأي مشكلة أخرى قد تمنعني من استخراج الصور. أنهيت عمليات الاستخلاص وبنيت أول نسخة من محرك بحث. بعد ذلك، انتقلت إلى أمور أخرى حتى الآن، عندما بدأت أركز على العالم العربي.
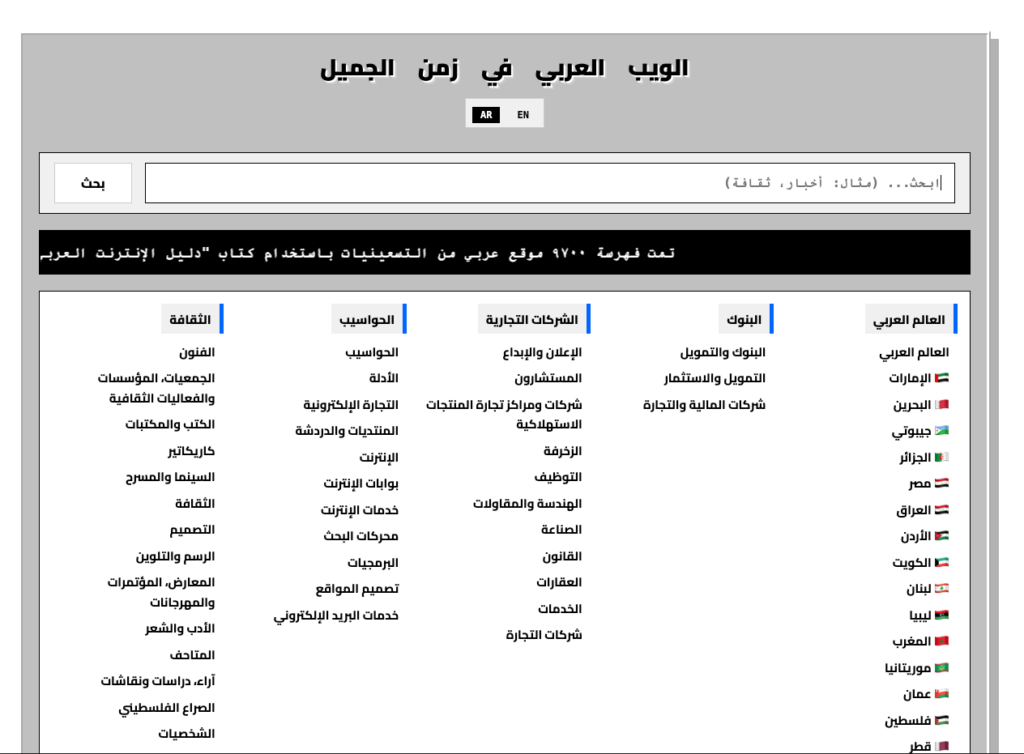
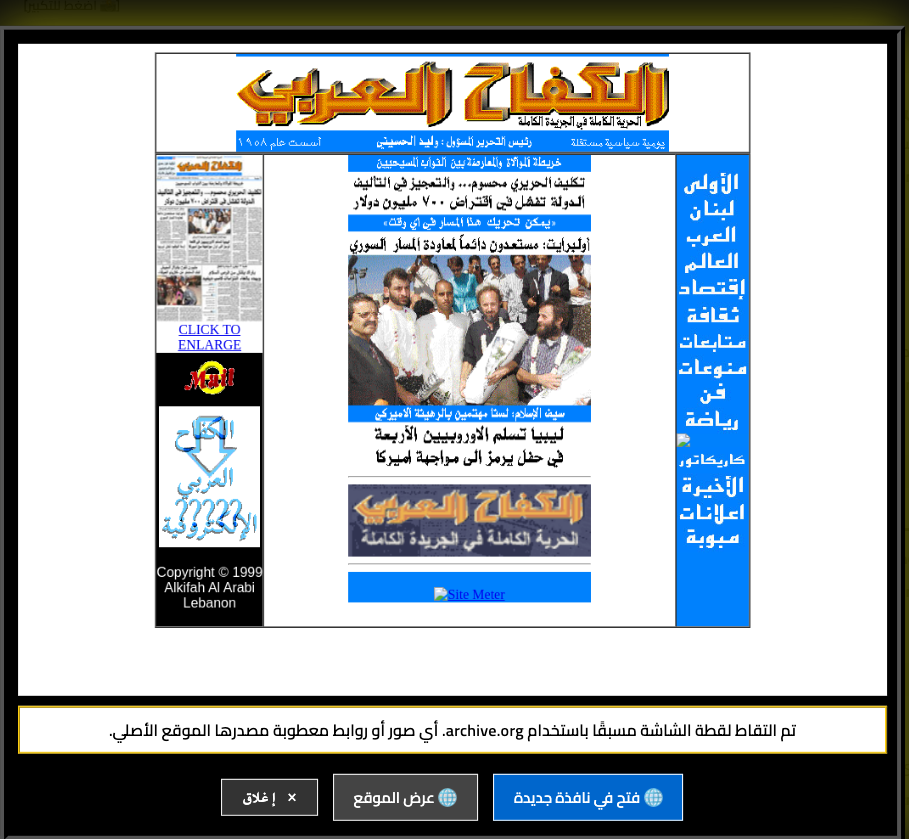
أعدت تصميم الموقع وجعلته متاحا باللغتين الإنجليزية والعربية. الصفحة الرئيسية تشبه محركات البحث في التسعينات، مثل محركات البحث التي بنيتها في الماضي. يمكنك إجراء بحث أو اختيار فئة. كل نتيجة عبارة عن رابط مصحوب بصورة مصغرة لصفحتها الرئيسية. النقر على الصورة المصغرة أو العنوان سيظهر نافذة بحجم كبير من لقطة الموقع الرئيسية للصفحة. ملاحظه: العديد من هذه المواقع قد تحتوي على صور معطلة، والتي للأسف ستظهر نفس الشيء في لقطات المواقع. في النافذة المنبثقة، لديك خيار الذهاب إلى النسخة المؤرشفة من الموقع وتصفح محتواه، إما في نفس النافذة نفسها أو كصفحة منفصلة.
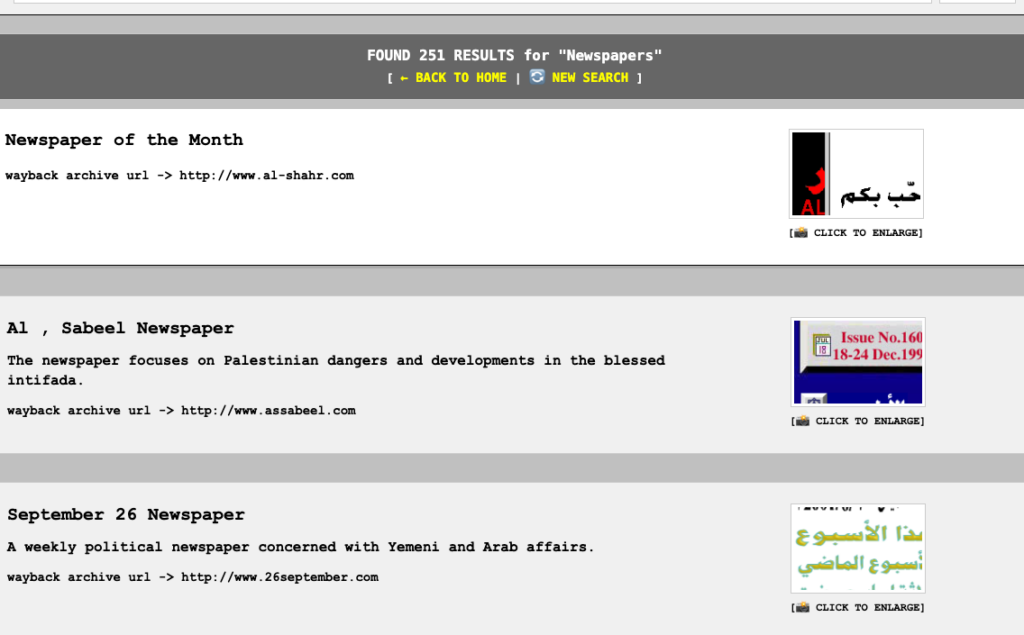
يحتوي الموقع على 9700 رابط حتى 15 أبريل 2026. أرغب في العثور على المزيد من قواعد البيانات للروابط من مواقع عربية في التسعينيات. وبهذا، آمل أن أتمكن من عرضها هنا كتحية للجيل الأول من الإنترنت في العالم العربي. ذا كنت تعرف أي من هذه القواعد، يرجى التواصل معي عبر tarek at infocomet.com
يرجى مراجعة الموقع https://retro.arabic.computer واستمتع بمشاهدة المواقع من الأزمنة القديمة.
The late nineties was a golden period for the Internet and the publishing of websites around the world, including the Arab world. Many of such sites no longer exist. However, thanks to archive.org, snapshots of many sites have been preserved. Several years ago, I found the Arab World Internet Directory 2002 book published by Arab Scientific Publishers at my parents’ house in Lebanon. The book contained thousands of website links from all over the Arab world. I contacted its publisher, Mr. Ghassan Chebaro, and requested permission to use the links in the book to build a working search engine for the Arab world that properly integrates with the archived screenshots at archive.org. In addition, I didn’t want to just have a link that goes to each site but rather have a predownloaded image of each site. This way, a user to the site can just look at a snapshot before deciding if they want to view the actual site at archive.org. I then proceeded with developing my code to extract around 12000 links from the book. At first, I was attempting to OCR the book until Mr. Chebaro gave me a Word document of the links, which saved me a lot of time in extracting the links. I also translated the descriptions in the book so that the site references will be represented in both Arabic and English. After that I developed a script to automatically capture the oldest screenshot that was still available on archive.org, take a thumbnail and a large image of each site’s homepage, and store it on my server. I also had to make the extraction script smart enough to handle retries, Internet disconnection, and any other issue that might stop it from extracting the images. I finished the extractions and built a first iteration of a search engine. After that, I moved on to other things until now, when I started focusing on the Arab world.
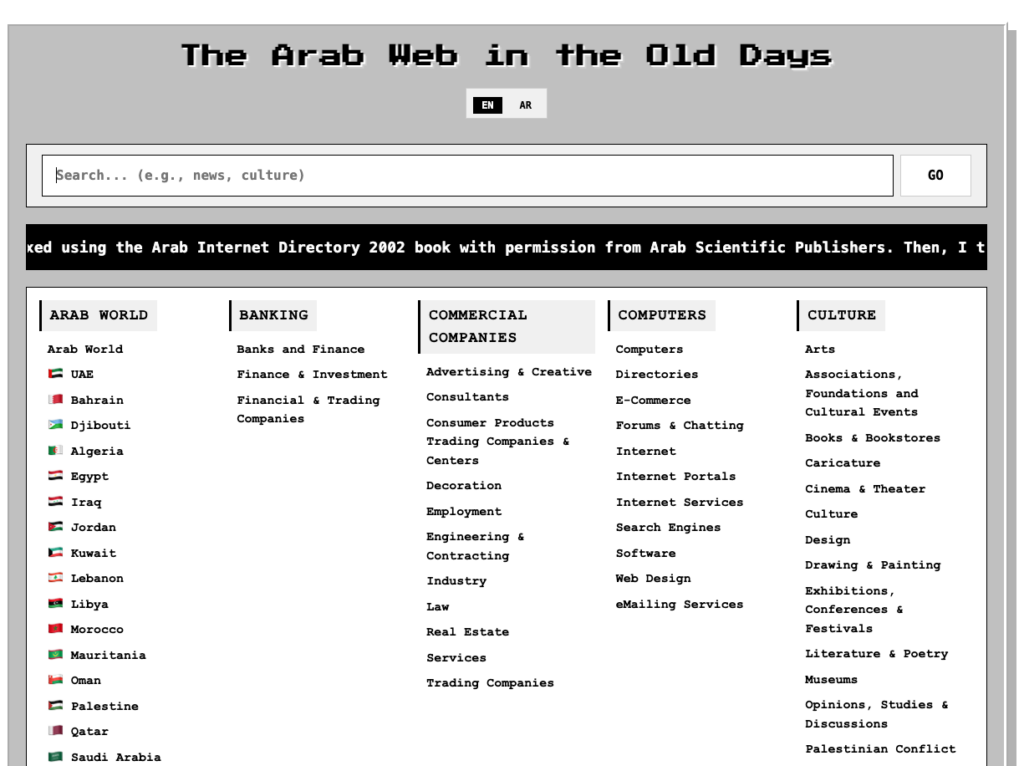
I redid the site and made it accessible in both English and Arabic. The home page is like search engines of the 90s. In fact, I developed two search engines back in the day. Doing a search or selecting a category yields a set of results. Each result is a link accompanied by a thumbnail photo of its homepage. Clicking on the thumbnail or the title will pop up a window with a large size of the homepage screenshot. Note, that many of these sites might have broken images, which, unfortunately, will show the same in the screenshots. In the popup window, you have a choice to go to the archived version of the site and browse its content, either in the same window itself or as a separate page.
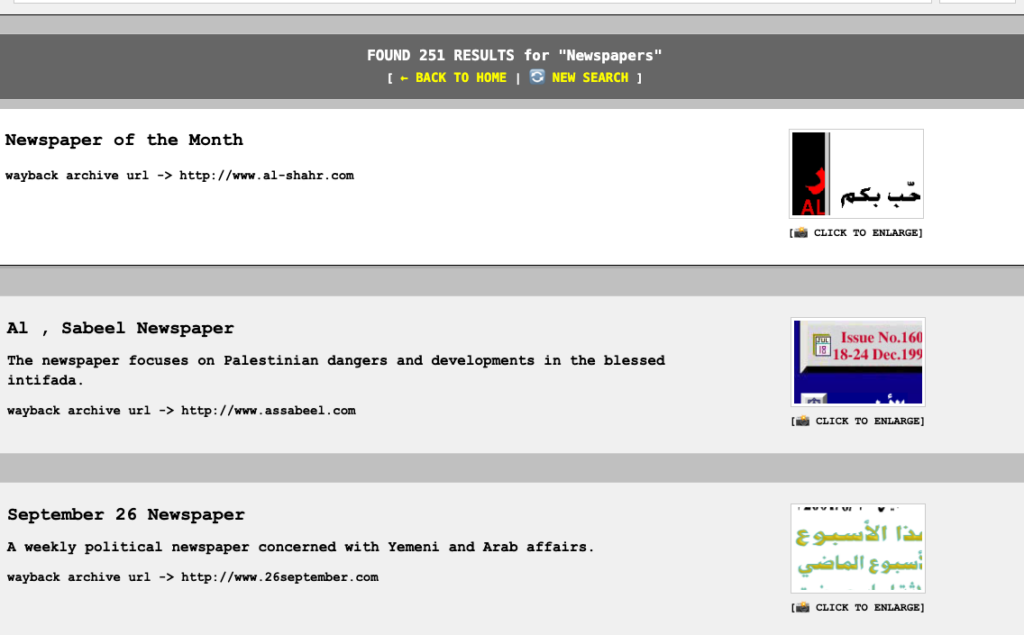
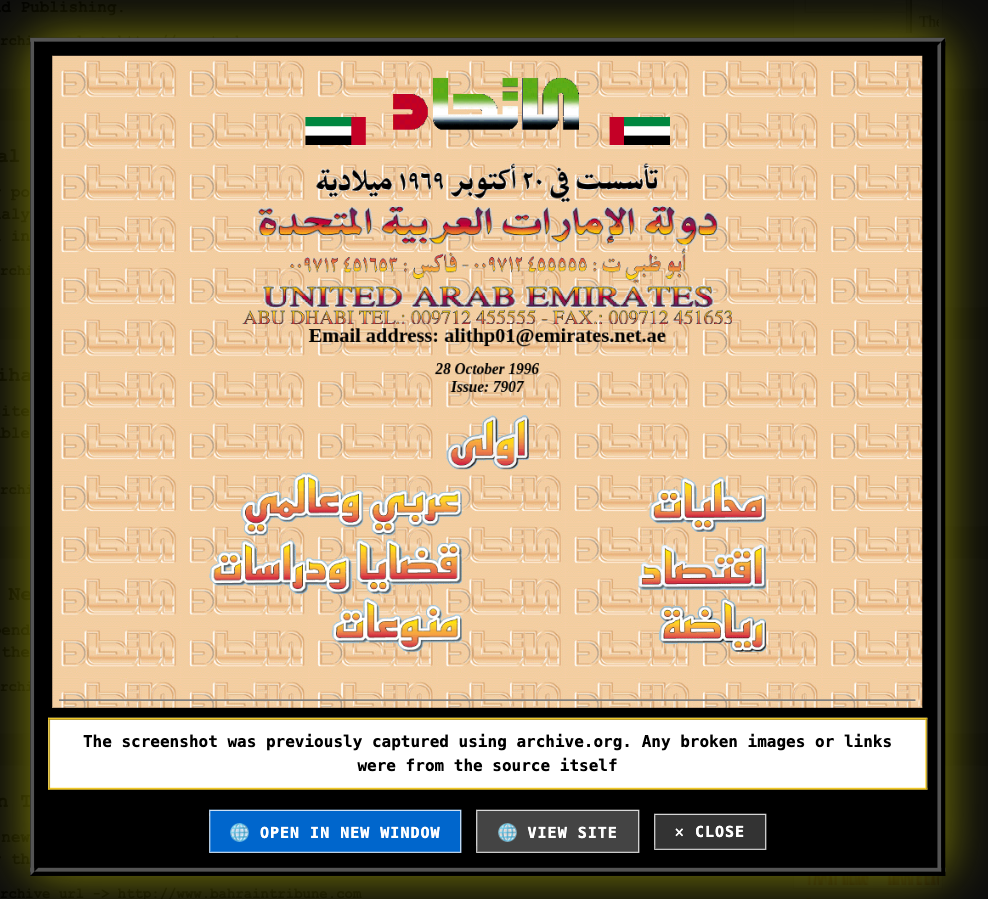
The site has 9700 links as of April 15, 2026. I wish to find more databases of links from Arab websites back in the nineties. With that, I hope that I can showcase them here as a tribute to the first Internet generation of the Arab world. If you know of any of such databases, please contact me at tarek at infocomet.com
Please check the website https://retro.arabic.computer and enjoy looking at sites from the old times.